Každý, kdo někdy vytvořil webové stránky, nebo ho zajímá, jak ty jeho oblíbené vypadaly před mnoha lety, má možnost si je prohlédout na tomto archivu.
Archive.org
Abyste si web prohlédli, najeďte na stránku https://archive.org/. Do vyhledávacího pole napiště adresu stránky, v mém případě je to tento web. Stačí napsat jen Cistepc.cz. Chvíli počkáte a ukáže se vám „kalendář“, kde jsou roky v řádku a pak měsíce a dny. Vyberte rok a pak následně den, kdy byl web archivován. Je to náhodně, nelze vybrat stejný den každý měsíc nebo rok. V prvním roce existence stránek tam mám jen 2 záznamy, kdy je možné se na web podívat. Zvolím tedy 28.března 2013.
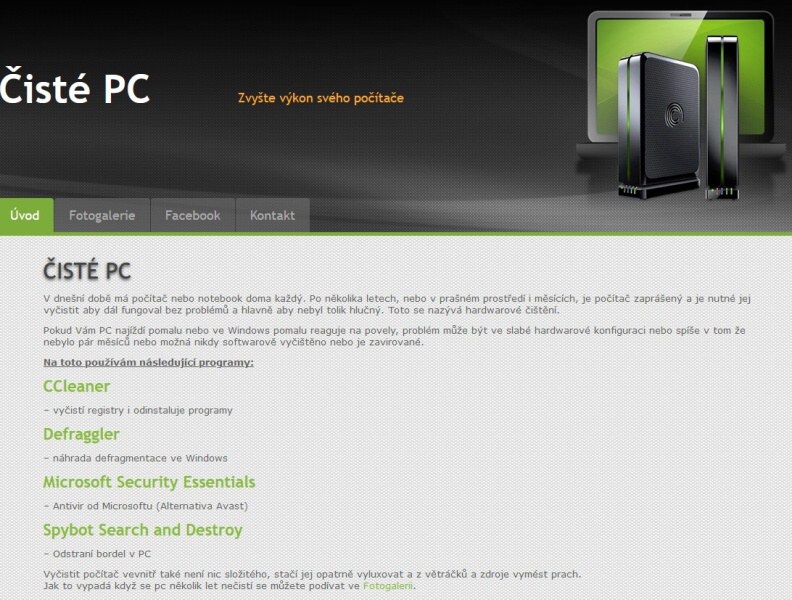
A takto stránky vypadaly, když jsem je začal dělat, byl to web statický, ještě tu ani nebyl blog, protože jsem ani nevěděl, co to blogovací systém WordPress je :) Hodně velké retro :))
Jak stáhnout obsah starého webu z Archive.org
Mnoho webů, které dříve fungovaly, ale majitel už se jim nechce věnovat, prostě neprodlouží a doména propadne. Jenže digitální stopa je tam a i obsah, který na stránkách byl, je po určitý čas i v archivu dostupný a to včetně fotek.
Stačí vybrat doménu, která vás zajímá a třeba jste ji koupili, najet podle postupu výše na archiv, vybrat den a obsah a pak stránku uložit. Ve Firefoxu to uděláte přes Soubor a Uložit stránku jako.
Tím se vám uloží celá včetně obrázků. Když je web malý, problém to není, pokud je větší s několika stovkami stránek, pak můžete využít Wayback Machine Downloader nebo placený Archivarix.
Video návod
Odkazy:
- Proč ještě mít doma pc, když 3x víc lidí prohlíží internet na mobilu
- Jak poslat balík přes Zásilkovnu
Buďte první kdo přidá komentář